How far are we from a Full-band Single-quantizer Tokenizer for General Audio?
Abstract
Audio Language Modeling (LM) has recently shown accelerated progress in various audio generation tasks. Audio tokenizers are neural networks that compress audio signals into discrete tokens that enables LM for audio, which have thus gained increased attention from industry and research communities. A full-band (48kHz) tokenizer is expected to reproduce realistic timbres of versatile audio sources in real world. Meanwhile, single-quantizer tokenizers have been reported to have codebook structures more compatible with audio LMs. However, most prior works focused on either full-band tokenization with multiple codebooks or limited-band tokenization with a single codebook, a trend followed by recent surveys and evaluation research on audio tokenization. In this paper, we adapted or proposed seven representative single-quantizer tokenizers and train them from-scratch on general audio at full-band. Comprehensive evaluations are done with a set of signal matching, perceptual, and distribution matching metrics. In our benchmark, we found some of our modified and proposed models competitive to strong existing models that use multi-layer quantizers or even a continuous bottleneck.
Tokenizer Architecture
| Fig. 1: A generalized visualization of audio tokenizer architecture. The transform f(x) → X is either signal-processing-based or data-driven, mapping audio waveforms x into a time-frequency (spectral) representation X. |
|---|
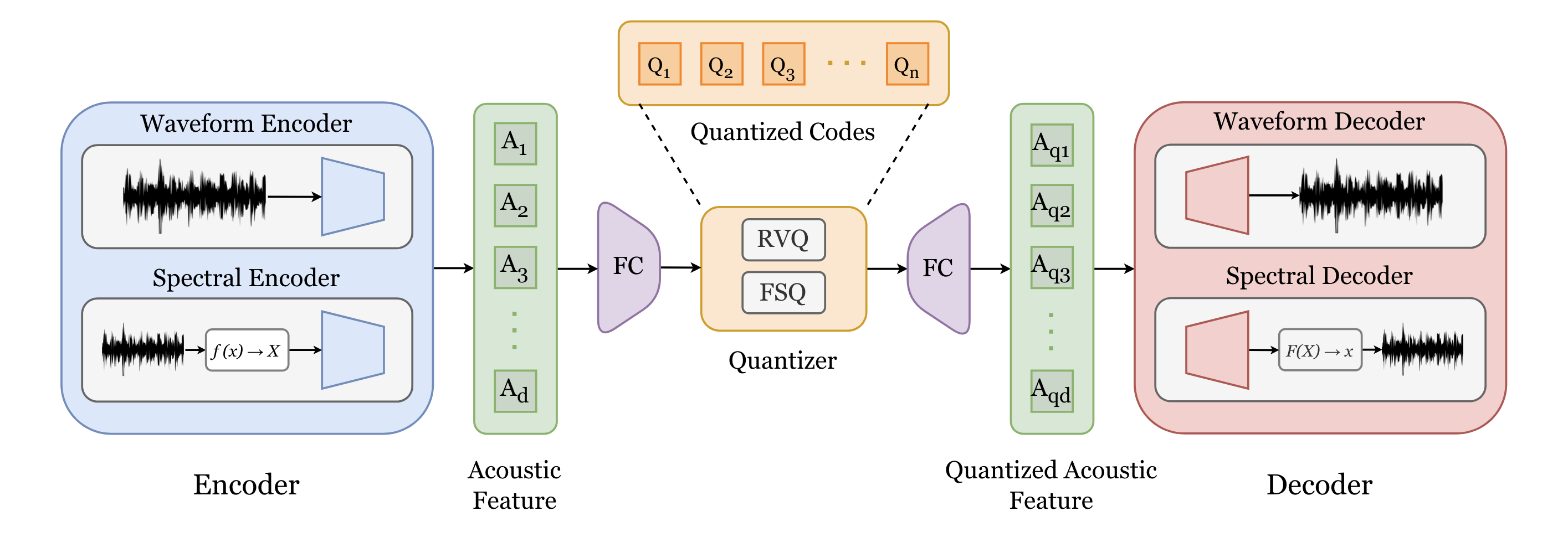
|
Speech samples (VCTK-48kHz)
Baselines
| Ground Truth - 48k | |||||
|---|---|---|---|---|---|
| Ground Truth - 16k | |||||
| Descript Audio Codec - 44k | |||||
| EnCodec - 48k | |||||
| SpectroStream - 48k |
Single-quantizer Tokenizers
| Descript Audio Codec - 44k (single codebook) | |||||
|---|---|---|---|---|---|
| EnCodec - 48k (single codebook) | |||||
| SpectroStream - 48k (single codebook) | |||||
| WavTokenizer - 48k | |||||
| BigCodec - 48k | |||||
| StableCodec - 48k | |||||
| XCodec2 - 48k | |||||
| TS3Codec - 48k | |||||
| Wav-Wav (Ours) | |||||
| Spec-Spec (Ours) |
General audio samples (AudioCaps-48kHz)
Baselines
| Ground Truth - 48k | |||||
|---|---|---|---|---|---|
| Ground Truth - 16k | |||||
| Descript Audio Codec - 44k | |||||
| EnCodec - 48k | |||||
| SpectroStream - 48k | |||||
| SoundCTM-VAE |
Single-quantizer Tokenizers
| Descript Audio Codec - 44k (single codebook) | |||||
|---|---|---|---|---|---|
| EnCodec - 48k (single codebook) | |||||
| SpectroStream - 48k (single codebook) | |||||
| BigCodec - 48k | |||||
| StableCodec - 48k | |||||
| XCodec2 - 48k | |||||
| Wav-Wav (Ours) | |||||
| Spec-Spec (Ours) |
BibTeX
TBAReference Implementations
- Descript Audio Codec: https://github.com/descriptinc/descript-audio-codec
- EnCodec: https://github.com/facebookresearch/encodec
- SpectroStream: https://github.com/magenta/magenta-realtime
- WavTokenizer: https://github.com/jishengpeng/WavTokenizer
- BigCodec: https://github.com/Aria-K-Alethia/BigCodec
- StableCodec: https://github.com/Stability-AI/stable-audio-tools
- XCodec2: https://github.com/zhenye234/X-Codec-2.0
- TS3Codec: No official implementation available see MagiCodec implementation
- SoundCTM-VAE: https://github.com/koichi-saito-sony/soundctm_dit_iclr